1 背景
扫描二维码随身看资讯
使用手机 二维码应用 扫描右侧二维码,您可以
1. 在手机上细细品读~
2. 分享给您的微信好友或朋友圈~
★ Redis24篇集合
在我们的《
Redis高可用之战:主从架构
》篇章中,介绍了Redis的主从架构模式,可以有效的提升Redis服务的可用性,减少甚至避免Redis服务发生完全宕机的可能。
它主要包含如下能力:
1. 故障隔离和恢复
:无论主节点或者从节点宕机,其他节点依然可以保证服务的正常运行,并可以手动或自动切换主从。
- 如果Slave库故障,则读写操作全部走到Master库中
- 如果Master库故障,则将Slave转成Master库,仅丢失Master库来不及同步到Slave的小部分数据
2. 读写隔离
:Master 节点提供写服务,Slave 节点提供读服务,分摊流量压力,均衡流量的负载。
3. 提供高可用保障
:主从模式是高可用的最基础版本,也是 sentinel 哨兵模式和 cluster 集群模式实施的前置条件。
主从架构模式虽然很强大,但依然存在一些的问题,我们知道,在衡量系统可用性这方面有个指标叫做 MTTR ,即平均修复时间。虽然主从模式支持手动切换,但是 我们从接收到服务故障预警到手动切换止损到恢复,这可能是一个比较长的过程。这期间的损失将难以计量,对于超高并发大系统是一个绝对灾难。 所以我们需要系统能自动的感知到Master故障,并选择一个 Slave 切换为 Master,实现故障自动转移的能力,提升 RTO 指数。这时候 哨兵模式 就可以支棱起来了。
平均修复时间(Mean time to repair,MTTR),是描述产品由故障状态转为工作状态时修理时间的平均值。
复原时间目标(Recovery Time Objective,RTO):是描述产品从故障到恢复原状的时间,优质架构要求我们尽量在1分钟左右恢复,一线互联网大厂的高并发场景0容忍。
2 什么是哨兵模式
在实际生产环境中,服务器难免会遇到一些突发状况:服务器宕机,停电,硬件损坏等等,一旦发生,后果不堪设想。
哨兵模式的核心还是主从模式的演变,只不过
相对于主从模式,在主节点宕机导致不可写的情况下,多了探活,以及竞选机制
:从所有的从节点竞选出新的主节点,然后自动切换。竞选机制的实现,是依赖于在系统中启动Sentinel进程,对各个服务器进行监控。如下图所示:

3 哨兵模式的职责能力
哨兵模式作为Redis高可用的一种运行机制,专注于对 Redis 实例(master、slaves)运行状态进行监控,并能够在主节点发生故障时通过一系列的操作,实现新的master竞选、主从切换、故障转移,确保整个 Redis 服务的可用性。
整体来说它有如下能力:
- 集群监控
- 故障监测与通知
- 自动故障转移(主从切换)
3.1 集群监控
哨兵模式的主要任务之一是监控Redis主从复制集群中的各个节点。它会定期检查主节点和从节点的健康状态,确保它们都在正常运行。
3.1.1 前置知识
1. 主观下线(sdown):
- sdown(主观不可用)是单个哨兵自己主观上检测到的关于Master的状态,从哨兵的角度来看,如果发送PING心跳后,在一定的时间内没有得到应有的回复,就达到了sdown的条件。
-
哨兵配置文件
sentinel.conf中down-after-milliseconds属性设置了判断主观下线的回复时间。

# sentinel down-after-milliseconds mymaster 30000 默认30s
sentinel down-after-milliseconds <masterName> <timeout>
这种机制是为了保证多个哨兵实例可以一起综合判断,避免单个哨兵( 因为自身请求超时、网络抖动等问题 )的误判,导致主库被下线。
2. 客观下线 (odown):
上面说了,Master是否下线不是单个Sentinel能够决定的,一般来说需要一定数量的哨兵,多个哨兵达成一致意见才能认为一个Master客观上已经宕机了。
上面的图可以看到,我们一般会有个Sentinel集群 ,这时候这个集群就发挥作用了,通过投票机制,超过指定数量(一般为半数)的Sentinel 都判断了『主观下线』 ,这时候我们就把 Master 标记为『客观下线』,代表它确实不可用了。
投票判定的数量是通过
sentinel.conf
配置的:
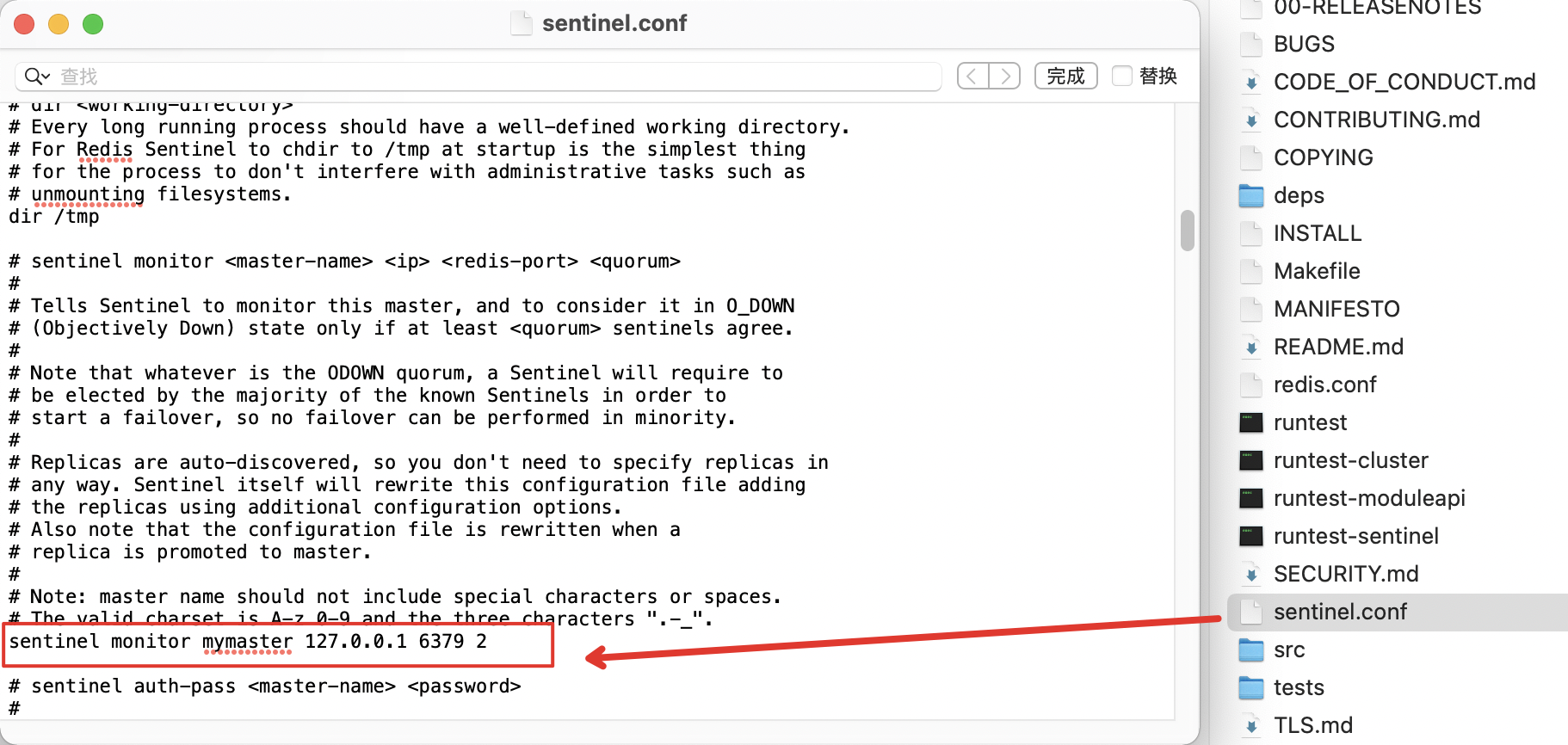
# sentinel monitor <master-name> <master-host> <master-port> <quorum>
# 举例如下:
sentinel monitor master 127.0.0.1 6379 2
这条配置项用于告知哨兵需要监听的主节点:
1、sentinel monitor:监控标识
2、mymaster:这边可以放上主节点的名称
3、192.168.11.128 6379:代表监控的主节点 ip,port。6379是redis常规端口。
4、2:判定的sentinel数量,果你有3个 Sentinel,并且 quorum 设置为 2,那么至少需要有2个 Sentinel 认定 Master 节点不可用时(sdown),才会触发故障转移,执行 failover 操作。

3.1.2 监控和通信逻辑
1. 哨兵(Sentinel)与主节点(Master)之间
- Sentinel通过定期(1s一次心跳包)向主节点发送PING命令来检查其状态
-
Sentinel启动后根据配置向Master发送
INFO指令,获取并保存所有哨兵(Sentinel)状态,主节点(Master)和从节点(Slave)信息。 - 主节点(Master)会记录所有从节点(Slave)和与它连接的哨兵(Sentinel)实例的信息。
2. 哨兵(Sentinel)与从节点(Slave)之间
-
从上面得知,Sentinel向Master发送
INFO命令,并获取所有Slave的信息 - Sentinel 根据 Master 返回的 Slave 列表,逐个与 Salve 建立连接,同样的定期向从节点发送PING命令来检查它们的状态
3. 集群中的哨兵(sentinel)之间实现通信
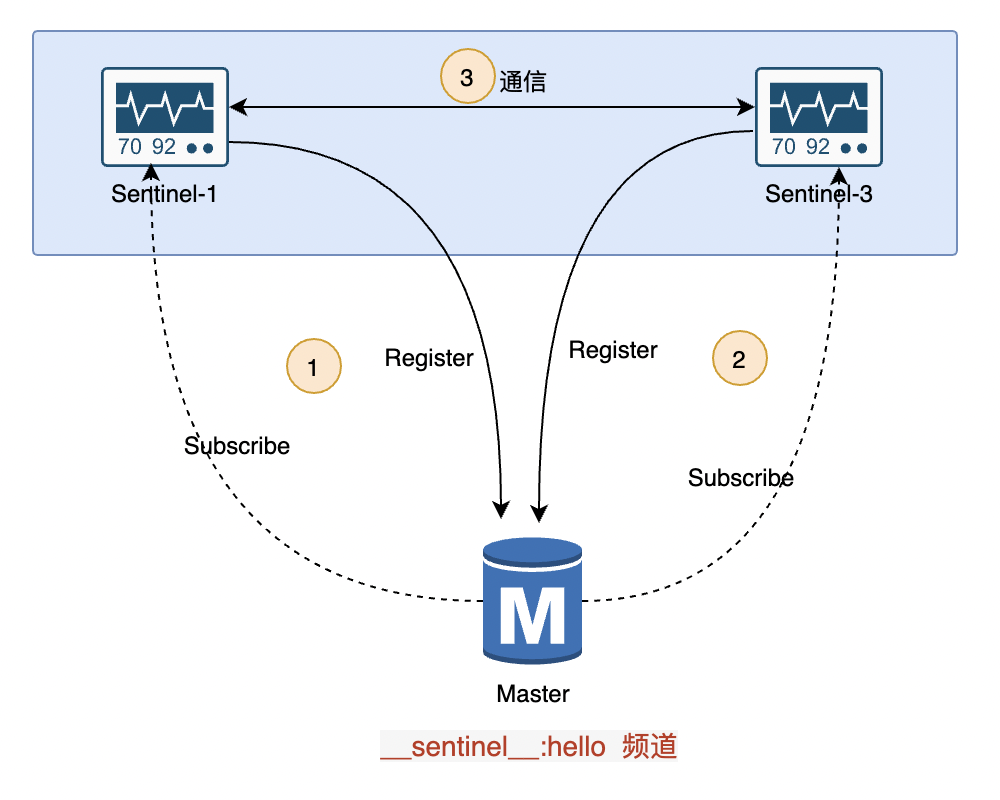
使用Redis的pub/sub 订阅能力实现哨兵间通信 和 Slave 发现。
哨兵之间可以相互通信,主要归功于 Redis 的 pub/sub (发布/订阅)机制。Master 有一个
__sentinel__:hello
的专用通信通道,用于哨兵之间发布和订阅消息。哨兵与 Master 建立通信之后,就可以利用 Master 提供发布/订阅机制发布自己的IP、Port等信息,同时订阅其他Sentinel发布的Name、IP、Port消息。
- Sentinel 建立与 Master 的通信
-
通过订阅Master的
__sentinel__:hello频道,当自身节点启动或更新其状态时,重新发布自己的当前状态和信息(Name、IP、Port消息) - 同时订阅其他哨兵发布的Name、IP、Port消息
- 互相发现之后建立起了连接,后续的消息通信就可以直接进行交互
★ 有没有觉得套路很熟悉,这个与微服务中的服务注册与发现,以及RPC通信类似的做法。请理解清楚图中1、2、3步骤。
4. 标记下线的过程
我们上面说过了,Sentinel进程启动之后,会定期(1s一次心跳包)向主节点发送PING命令来检查其状态,检查看状态是否正常响应。
- 如果Slave 没有在规定的时间内响应 Sentinel 的 PING 命令 , Sentinel 会认为该实例已经挂了,将它tag为下线状态(offline)。
- 同理,如果Master 没有在规定时间响应 Sentinel 的 PING 命令,也会被判定为 offline 状态,为后续的主从自动切换做好准备工作。
3.2 主从动态切换(故障转移)
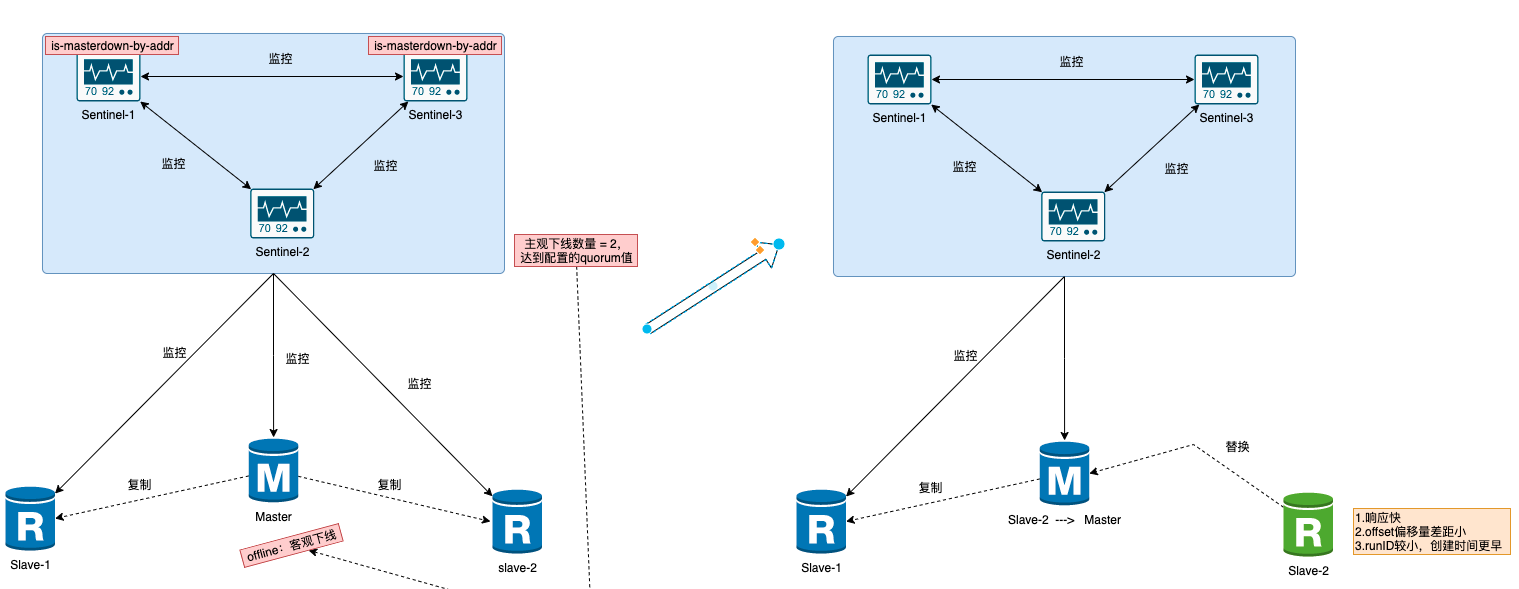
当master出现故障之后,Sentinel 的一个很核心的作用,就是从多个Slave中选举出一个新的Master,以达到故障转移的目的。核心步骤如下:
-
哨兵会心跳包定时给主节点发送
publish sentinel :hello,如果超时不响应则标记 主观下线(sdown)。超时时间配置down-after-milliseconds前面说过了。 -
哨兵标记主节点 sdown 只是单个哨兵行为,需要往Sentinel集群发布消息说明这个主节点挂了,发送的指令
sentinel is-master-down-by-address-port。 -
其余的哨兵接收到指令后,也对Master进行探活,如果收不到响应同样标记
sdown,同时发送指令sentinel is-master-down-by-address-port到Sentinel内网,这样哨兵内部群会再收到 Master 挂了的消息。 -
汇总计票,超过半数(通过
quorum配置)就认为Master节点确实不行了,然后修改其状态为odown, 既客观下线。注意哨兵总数尽量为单数,避免『脑裂』。 -
一旦认为主节点
odown后,哨兵就会进行选举新Master的工作,这很重要。 -
选举新的Master,由指定的哨兵进行选举。选举条件:
- 响应慢的过滤掉,Sentinel会给所有的Redis从节点发送信息,响应速度慢的就会被优先过滤掉,说明健壮性不够。
-
判断 offset 偏移量,选择数据偏移量差距最小的,即
slave_repl_offset与master_repl_offset的进度差距,其实就是比较 Slave 与 原 Master 复制进度差距。 假如 slave2 的 offset 为90, slave1 偏移量 为100 那么哨兵就会认为slave2的网络不佳,优先选择slave1为新的主节点。 - slave runID,在优先级和复制进度都相同的情况下,选用runID最小的,runID越小说明创建时间越早,优先选为Master,先来后到原则。
等这几个条件都评估完,我们就会选择出最合适的Slave,把他推举为新的Master。
3.3 信息通知
等推选出最新的Master之后,后续所有的写操作都会进入这个Master中。所以需要尽快广播通知到所有的Slave,让他们重新
replacaof
到 Master上,重新建立
runID
和
slave_repl_offset
,来保证数据的正常传输和主从一致性。
4 总结
Redis 哨兵机制是实现 Redis 高可用的核心手段,相比之前的《
Redis高可用之战:主从架构
》更具
自动化和时效性。
它的核心功能职责如下:
- 集群监控: 哨兵模式的主要任务之一是监控Redis主从复制集群中的各个节点。它会定期检查主节点和从节点的健康状态,确保它们都在正常运行。
- 故障检测与通知: 当检测到主节点出现故障或不可用时,哨兵会立即发送报警通知给其他哨兵。这有助于及时发现并处理潜在的问题。
- 自动故障转移 :在检测到主节点故障后,哨兵会自动触发故障转移机制。它会选择一个健康的从节点,将其提升为新的主节点,并通知其他从节点更新复制目标。这样,整个系统可以在主节点故障时保持可用性。
- 配置更新与通知 :在故障转移完成后,哨兵会更新相关配置,并将新的主节点地址通知给客户端。这确保了客户端可以连接到新的主节点并继续进行操作。


































- 1
加查之花 正版
- 2
爪女孩 最新版
- 3
捕鱼大世界 无限金币版
- 4
企鹅岛 官方正版中文版
- 5
球球英雄 手游
- 6
内蒙打大a真人版
- 7
烦人的村民 手机版
- 8
跳跃之王手游
- 9
蛋仔派对 国服版本
- 10
情商天花板 2024最新版
 加查之花 正版
加查之花 正版 爪女孩 最新版
爪女孩 最新版 捕鱼大世界 无限金币版
捕鱼大世界 无限金币版 企鹅岛 官方正版中文版
企鹅岛 官方正版中文版 球球英雄 手游
球球英雄 手游 内蒙打大a真人版
内蒙打大a真人版 烦人的村民 手机版
烦人的村民 手机版 跳跃之王手游
跳跃之王手游 蛋仔派对 国服版本
蛋仔派对 国服版本 情商天花板 2024最新版
情商天花板 2024最新版 黑暗密语2内置作弊菜单 1.0.0 安卓版
黑暗密语2内置作弊菜单 1.0.0 安卓版 驱动事务游戏汉化版 0.3.5 安卓版
驱动事务游戏汉化版 0.3.5 安卓版 地铁跑酷忘忧10.0原神启动 安卓版
地铁跑酷忘忧10.0原神启动 安卓版 猫落家伙最新版 1.4 安卓版
猫落家伙最新版 1.4 安卓版 芭比公主宠物城堡游戏 1.9 安卓版
芭比公主宠物城堡游戏 1.9 安卓版 无尽对决国际服最新版本 1.7.70.8402 安卓版
无尽对决国际服最新版本 1.7.70.8402 安卓版 挂机小铁匠游戏 122 安卓版
挂机小铁匠游戏 122 安卓版 咸鱼大翻身游戏 1.18397 安卓版
咸鱼大翻身游戏 1.18397 安卓版 火影忍者云游戏版最新版 4.7.1.3029701 安卓版
火影忍者云游戏版最新版 4.7.1.3029701 安卓版 史诗幻想5 1.0.51 安卓版
史诗幻想5 1.0.51 安卓版